02:00
Proportional odds + Probit regression
Feb 12, 2024
Effect of arrival mode on waiting time
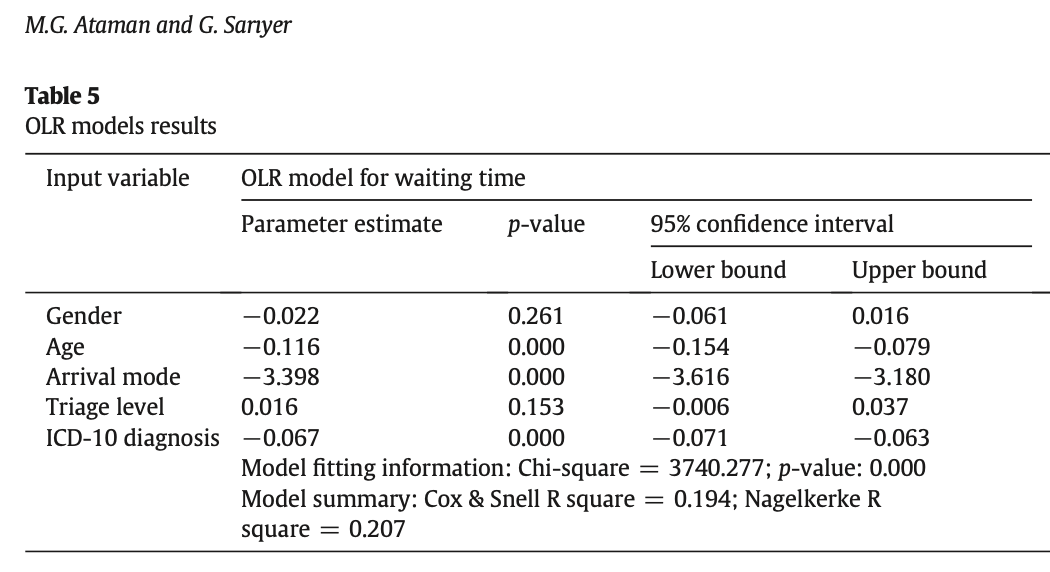
Waiting time model output from Ataman and Sarıyer (2021)
The variable arrival mode has two possible values: ambulance and walk-in. Describe the effect of arrival mode on waiting time. Note: The baseline category is walk-in.
Effect of triage level
Consider the full output with the ordinal logistic models for wait and treatment times.
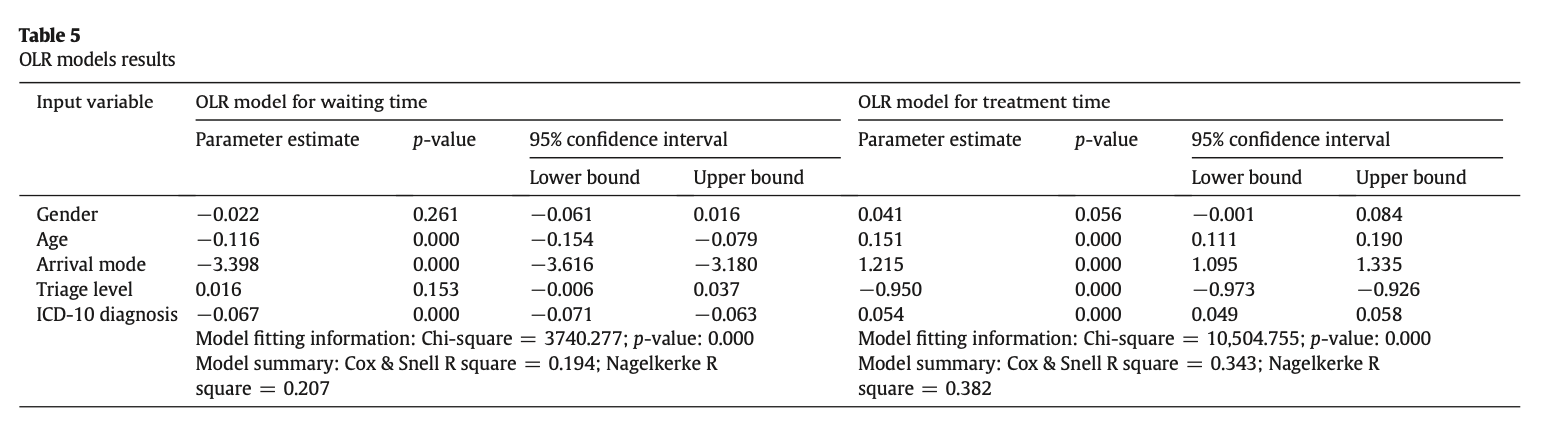
Waiting and treatment time model output from Ataman and Sarıyer (2021).
Use the results from both models to describe the effect of triage level on waiting and treatment times. Note: The baseline category is green.
Impact of nature documentary
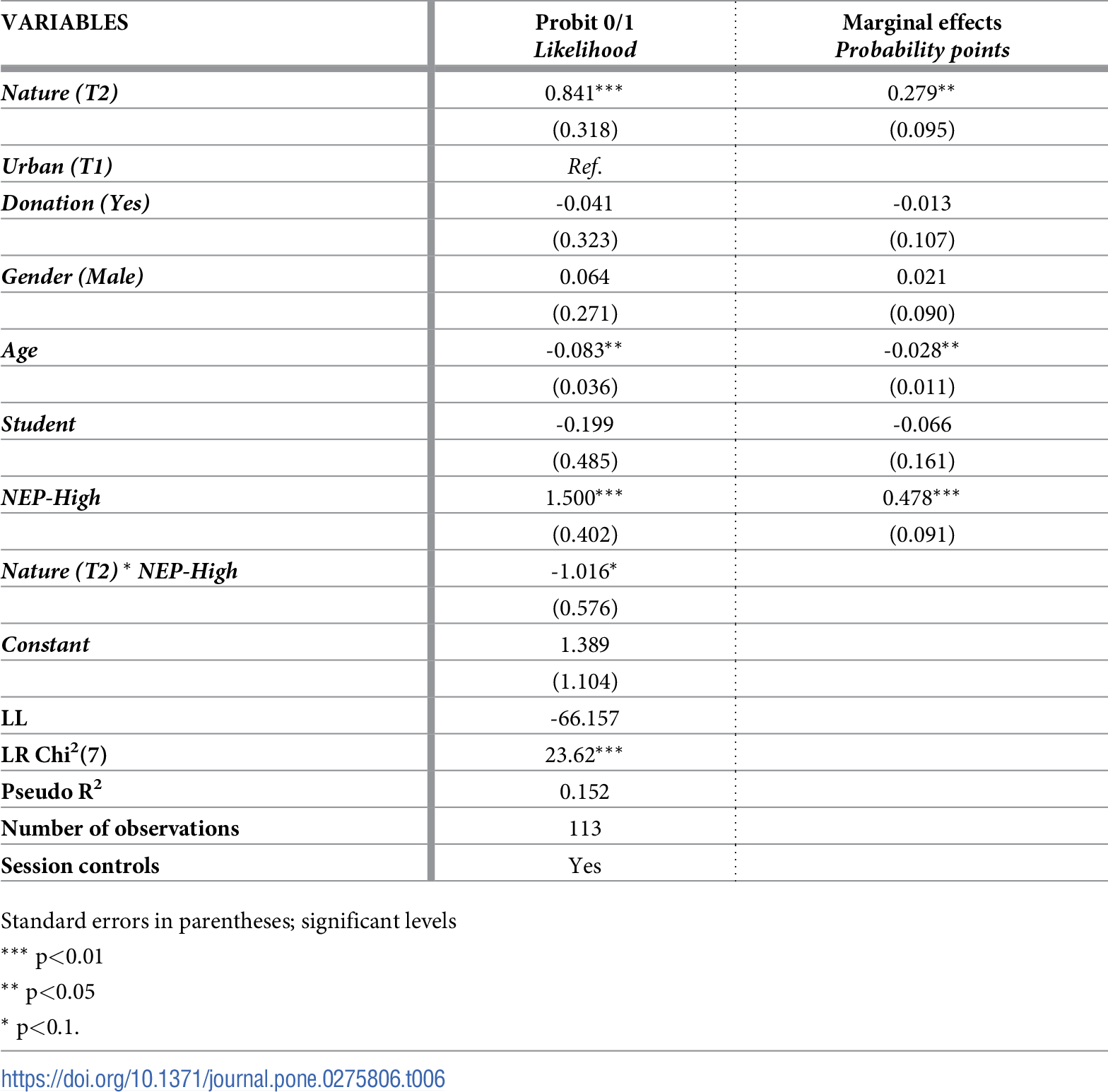
Interpret the effect of watching the nature documentary Nature (T2) on recycling. Assume NEP is low, NEP-High = 0.
References
![]()
Ataman, Mustafa Gökalp, and Görkem Sarıyer. 2021. “Predicting Waiting and Treatment Times in Emergency Departments Using Ordinal Logistic Regression Models.” The American Journal of Emergency Medicine 46: 45–50.
Ibanez, Lisette, and Sébastien Roussel. 2022. “The Impact of Nature Video Exposure on Pro-Environmental Behavior: An Experimental Investigation.” Plos One 17 (11): e0275806.
McNulty, Keith. 2021. Handbook of Regression Modeling in People Analytics: With Examples in r and Python. CRC Press.
Roback, Paul, and Julie Legler. 2021. Beyond multiple linear regression: applied generalized linear models and multilevel models in R. CRC Press.